

As mentioned in previous posts I have build myself a nice little dashboard with all the important things I need to track for my personal life.
One of those things is tracking my exercise, as most data-minded people trying to get in shape I like to track everything in Strava.
I already have Airflow running in raspberry pi (based on this excellent tutorial) on my own network so I figured instead of the usual cron job I would go ahead and set the task to be accomplished by Airflow.
Test Setup
In order to test it I modified the default docker-compose airflow from the official airflow page.
The two main changes that I had to do to the docker deployment were to add Minio to emulate S3 (in my real deployment I used my AWS S3 connection) and to make sure that pydantic is installed into our docker containers.
Adding Minio
Minio allows me to emulate the S3 connection on my machine, furthermore the same hooks used in Airflow work for both AWS S3 and Minio.
In our docker-compose we just add minio under the services:
...
services:
...
minio:
image: minio/minio:RELEASE.2020-06-22T03-12-50Z
volumes:
- s3:/data
ports:
- "9000:9000"
command: server /data
environment:
MINIO_ACCESS_KEY: AKIAIOSFODNN7EXAMPLE
MINIO_SECRET_KEY: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
volumes:
...
s3:
Now if we do docker-compose up we will spin up a container with Minio.
The dashboard will be accessible at localhost:9000. We just use the default Access Key and Secret to login
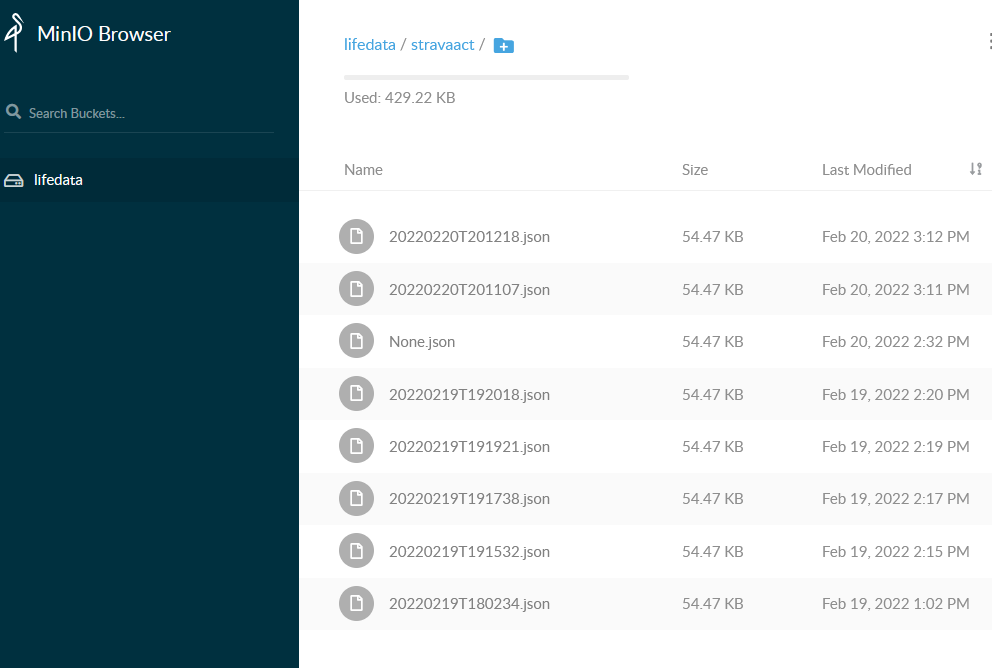
Extending our Airflow Image
Now there are a million ways to expand out docker images, since this is the just a test setup to develope locally I went with the easiest one. Under docker_images we create oud dockerfile as follows:
FROM apache/airflow:2.0.2
RUN pip install --user --no-cache-dir pydantic
This makes sure that pydantic is installed into our image.
Now we need to change the default docker-compose.yaml to use this.
We modify the following:
version: '3'
x-airflow-common:
&airflow-common
build:
context: ./docker_image
...
Now instead of pulling the base image, docker-compose will build using our dockerfile instead.
Setting up Airflow Connections and Variables
First Steps
In order to not have bare sensitive information available on our docker-compose.yaml we will define the connections and other sensitive information in directly into airflow.
We could do this from the cli, but I actually prefer to use the admin dashboard.
to get started we initialize our docker image (if using the test setup)
docker-compose up initdb
That will startup our postgres db that airflow uses to function. Once that process is complete we can go ahead and do
docker-compose up
and that will boot up our whole airflow stack, including redis, postgres and minio.
Airflow Dashboard
Now we can log into the admin dashboard at localhost:8080.
We just use the default user (if using docker-compose) for me this is the super secure airflow / airflow.
Airflow Variables
On the admin dashboard we are going to setup our Strava API keys.
Airflow will treat anything ending in _SECRET as a password and block accordingly.
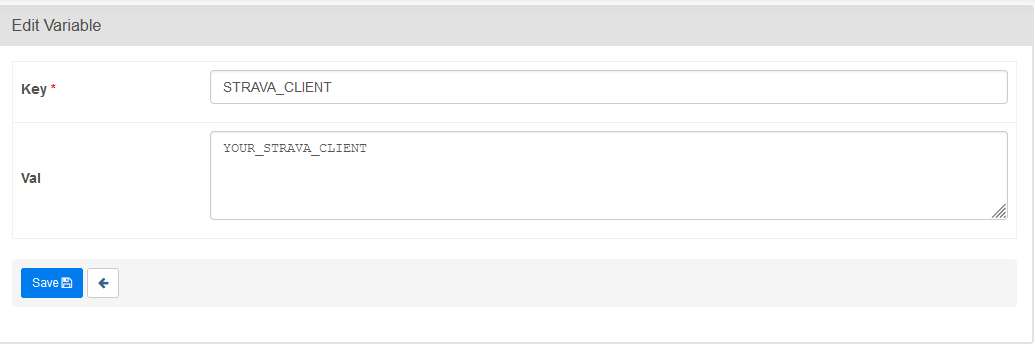
We follow the same process to setup our STRAVA_CLIENT_SECRET.
Withing our airflow dag declaration these can be accessed with the airflow.models module.
from airflow.models import Variable
strava_client = Variable.get('STRAVA_CLIENT`)
Airflow Connections
One of the main benefits of Airflow is that it has a large amount of providers with predefined hooks and connections ready to roll. Most importantly for us, there are redis, S3 and Postgres provider packages.
The provider packages also provide us with predefined connection types, we can define these connections from the dashboard.
We setup the following connections (in my case they were already running in a raspberry pi in my localhost)
Postgres (stores our daily dash information):
conn_id : rasp-srv-daily-dash (or whatever you want to call it)
conn_type : Postgres
description: Connection to daily dash db
host: localhost (or wherever you just your db)
schema: myschema
login: myuser
password: mypasswed
port: 5432
Redis (We are going to use a instance of redis to store our api tokens)
conn_id: rasp-srv-redis
conn_type: Redis
description: Connection to redis holding short term tokens
host: localhost
port: 6379
Finally we need to setup the S3 connection, this actually took me a while to figure out. The connection to S3 is not well defined in the dashboard. In order to use it we need to pass most of the connection arguments under the extra section of the connection.
Minio
conn_id: docker-minio
conn_type: S3
description: localhost connection to Minio Docker
extra: {
"host":"http://minio:9000",
"aws_access_key_id":"AKIAIOSFODNN7EXAMPLE",
"aws_secret_access_key":"wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY"}
Now accessing these connections from our dag is relatively simple. For example accessing the Redis Hook just requires to do:
from airflow.providers.redis.hooks.redis import RedisHook
redis_h = RedisHook(redis_conn_id='rasp-srv-redis')
redis_client = redis_h.get_conn()
Now that we are all setup we can actually write our DAG.
Writing the DAG
First we will write our two separate steps:
- Download Data from Strava API and push to an S3 Bucket
- Download Data from an S3 Bucket and push to Postgres
This is a bit of overkill for our process. We could instead store the data in a local drive or just pass the whole data string in XCOM. While that would work perfectly fine for this purpose, I prefer to write it with best practices in mind.
- We use S3 instead of a local drive or file share because it will allow us to rerun steps, and also because if running this across multiple workers we are not guaranteed that they will have access to the same local resources.
- XCOM is not really meant to communicate a large amount of data, its more for pointers or addresses to where the data is stored or task instance information.
Pulling from the API
We will use an almost identical process to the one we have used in the pass to pull from the Strava API.
We will however greatly simplify it by using the excellent requests_oauthlib. To handle a lot of our token updating.
We are using redis to store our token. I generated an already authorized token using postman and outside of the workflow stored it into our redis instance.
Now we can make sure to setup our redis data store with:
def __get_strava_data(**_):
# Get API connection information
client_id = Variable.get(STRAVA_CLIENT)
client_secret = Variable.get("STRAVA_CLIENT_SECRET")
token_url = "https://www.strava.com/oauth/token"
refresh_url = token_url
# To use requests-oauth we need to setup the extra parameter
extra = {
'client_id': client_id,
'client_secret': client_secret
}
# Define redis connection
redis_h = RedisHook(redis_conn_id='rasp-srv-redis')
redis_client = redis_h.get_conn()
# define how we store the token in redis
def token_saver(token):
token_dict = dict(token.items())
redis_client.set('STRAVA_TOKEN', json.dumps(token_dict))
token = redis_client.get('STRAVA_TOKEN')
# Convert properly
token = json.loads(token)
That takes care of getting and setting a token in redis. Now we need to create our oauth client.
client = OAuth2Session(client_id, token=token,
auto_refresh_kwargs=extra,
auto_refresh_url=refresh_url,
token_updater=token_saver)
As we see we are using auto_refresh, so we need to pass all that information.
Finally we need to get the information from the API. We create some simple error caching to help us with our airflow logs.
def _get_strava_data(**_):
client_id = Variable.get("STRAVA_CLIENT")
client_secret = Variable.get("STRAVA_CLIENT_SECRET")
token_url = "https://www.strava.com/oauth/token"
refresh_url = token_url
extra = {
'client_id': client_id,
'client_secret': client_secret
}
redis_h = RedisHook(redis_conn_id='rasp-srv-redis')
redis_client = redis_h.get_conn()
def token_saver(token):
token_dict = dict(token.items())
redis_client.set('STRAVA_TOKEN', json.dumps(token_dict))
token = redis_client.get('STRAVA_TOKEN')
token = json.loads(token)
logging.info(token)
activities_url = 'https://www.strava.com/api/v3/athlete/activities?'
try:
client = OAuth2Session(client_id, token=token,
auto_refresh_kwargs=extra,
auto_refresh_url=refresh_url,
token_updater=token_saver)
response = client.get(activities_url)
logging.info(response)
if response.status_code != 200:
logging.error('FAILED API CALL TO API')
raise ConnectionError
except Exception as e:
logging.critical('Could not download from API {}'.format(e))
else:
logging.info('Data Successfully Downloaded')
return response
This function handles communicating with the API and returns the response.
Now we take full advantage of the connections Airflow provides and we use the S3Hook to handle the upload of the data to Minio.
def _download_strava_to_s3(ts):
response = _get_strava_data()
data = response.json()
bucket_name = 'lifedata'
logging.info('File name {}'.format(ts))
key = f"stravaact/{ts}.json"
s3_hook = S3Hook(aws_conn_id='docker-minio')
s3_hook.load_string(
string_data=json.dumps(data),
key=key,
bucket_name=bucket_name
)
return key
Now the data is function is pretty self explanatory.
We call our api function and then use our S3_hook to store the data into a bucket called lifedata into a file names with a timestamp. Note that this will fail if the bucket doesn't exists so we have to make sure it exists ahead of time.
In previous versions I was using ts_nodash which is an airflow macro that gets replaced using jinja templating. However using Airflow2.0 TaskFlow I was having problems accessing macros like that so now its just a passed string
Pulling from S3 and Storing into the DB
Now that the file is stored in our S3 bucket we need a function to pull a file from s3 when given the appropriate key and the pushes that into our PostgresDB.
Pulling the file is really easy
def _upload_s3_to_db(key_name: str)
key = key_name
s3_hook = S3Hook(aws_conn_id='docker-minio')
data = s3_hook.read_key(
key,
bucket_name='lifedata'
)
Thats it, airflow hooks make it very easy.
For storing the data into Postgres, I take a perhaps overly complicated approach, however I like to keep the same setup as I did defining the rest of the dashboard api.
First we define our pydantic class, this will perform validation on the data and avoid issues trying to push data.
from pydantic import BaseModel
from typing import Optional
from datetime import datetime
class StravaActivityCreate(BaseModel):
name: str
type: str
start_date: datetime
distance: float
moving_time: int
average_speed: Optional[int] = None
max_speed: Optional[float] = None
average_cadence: Optional[float] = None
average_heartrate: Optional[float] = None
weighted_average_watts: Optional[float] = None
kilojoules: Optional[float] = None
class StravaActivity(StravaActivityCreate):
id: int
class Config:
orm_mode = True
Now we have a way to force our downloaded data into the appropriate class to then be pushed into our table. In theory we could also define our models like we did in the past. But I took a bit of a shortcut and just chose to reflect tour preexisting database.
We will use from airflow.hooks.postgres_hook import PostgresHook to handle the connection to our DB.
from airflow.hooks.postgres_hook import PostgresHook
from sqlalchemy.orm import sessionmaker
from sqlalchemy.dialects.postgresql import insert
from sqlalchemy.ext.automap import automap_base
import json
....
def _upload_s3_to_db(key_name: str):
...
data = json.loads(data)
postgres_hook = PostgresHook(postgres_conn_id='rasp-srv-daily-dash')
engine = postgres_hook.get_sqlalchemy_engine()
Base = automap_base()
Base.prepare(engine, reflect=True)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
I really appreciate the built in airflow get_sqlalchemy_engine() as it helps simplify our setup.
Now that we have taken care of our Postgres connection and creating our model and validation we have to actually insert our data into the database. We will use the context lib to handle our database connection session, making sure it rollbacks and finishes properly.
...
from contextlib import contextmanager
def _upload_s3_to_db(key_name: str):
@contextmanager
def get_db():
db = SessionLocal()
try:
yield db
db.commit()
except Exception:
logging.error('Could not write to DB')
db.rollback()
raise
finally:
db.close()
with get_db() as db:
for x in data:
logging.info(x)
ST = StravaActivity.parse_obj(x)
ST_up = StravaActivityCreate.parse_obj(x)
stmnt = insert(Base.classes.strava_activity).values(ST.dict())
stmnt = stmnt.on_conflict_do_update(
index_elements=['id'], set_=ST_up.dict())
db.execute(stmnt)
We iterate over every element of our obtained json and the parse the object using our pydantic classes. We will create both pydantic models for both insert and update. This also has the advantage of dumping all the extra fields that we do not need form the API.
Since I am only handling the data for myself I can just generate a generic UPSERT of all the pulled data to the database. Because of that we do not use the general approach of using db.add(StravaActivity). Instead we take advantage of predefined postgres insert in sqlalchemy which allows ups to define an on_conflict_do_update class. This allows us to generate a statement that we will then UPSERT into Postgres.
Putting it all together
Now that we have defined the functions to actually do the work we need to create our actual DAG, this will inform Airflow how to chain the tasks together and the frequency of it.
Since our tasks are all written in python we will go ahead and use the TaskFlow API newly define in 2.0. Not going to lie, previously defining the dags in the traditional way would get slightly too messy for my taste. Not all operators need to be in python for this to work, but those are the only ones we are currently using.
First we define our dag using the @dag decorator.
from airflow.decorators import task, dag
@dag(
start_date=airflow.utils.dates.days_ago(1),
schedule_interval="@hourly",
max_active_runs=1)
def strava_data_pipeline():
...
We set it to run hourly, give it a start date, and to only run 1 at a time (again its just pulling my data).
Now we will define each of our tasks:
from airflow.decorators import task, dag
from airflow.operators.python import get_current_context
def strava_data_pipeline():
@task()
def get_data_from_strava():
context = get_current_context()
ts_nodash = context['ts_nodash']
key = _download_strava_to_s3(ts_nodash)
return key
@task()
def upload_s3_data_to_db(key: str):
_upload_s3_to_db(key)
key_id = get_data_from_strava()
upload_s3_data_to_db(key_id)
With the TaskFlow API this is extremely simple, vs the previous way having to define PythonOperator.
We just use the @task() decorator each function and make sure that the information that needs to pass between the tasks is returned by the function. In our case its just the bucket key.
The TaskFlow API takes care of the XCOM communication so we don't have to deal with it.
One thing that gave me some issues is that while the documentation states that we could just do
def get_data_from_strava(ts_nodash = None)to pass the ts_nodash macro, I could nto get that to work. We solve this by getting the dags current context withget_current_context()and pulling the correct key from the dictionary.
Finally we can just fire of our dag as follows:
# [START dag_invocation]
strava_task_dag = strava_data_pipeline()
# [END dag_invocation]
If we log into our Airflow Dashboard we will see our new dag (which we saved into our dag folder).
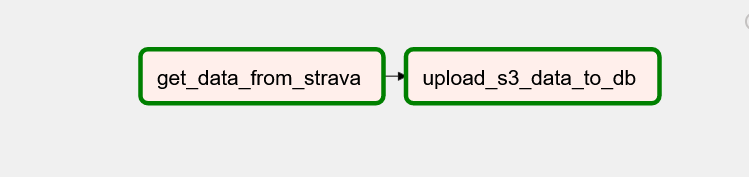
We can trigger our dag to see if it works. We will see both tasks status.

The whole setup can be accessed on my github